Encoding Event Data
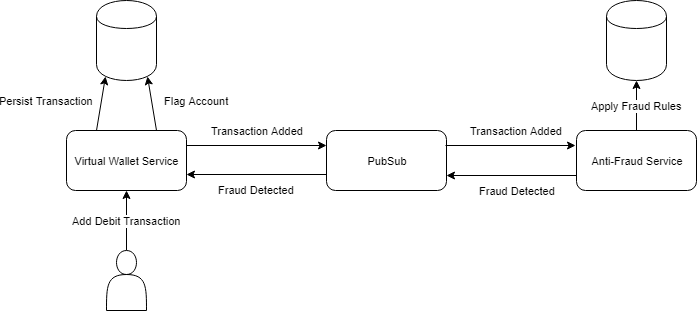
The event data needs to contain all the domain data that could be required by the services that will consume the events. This will differ for every event. For example, the “Transaction Added” event in the virtual wallet could have transaction ID, transaction type, amount, account ID and transaction date fields.
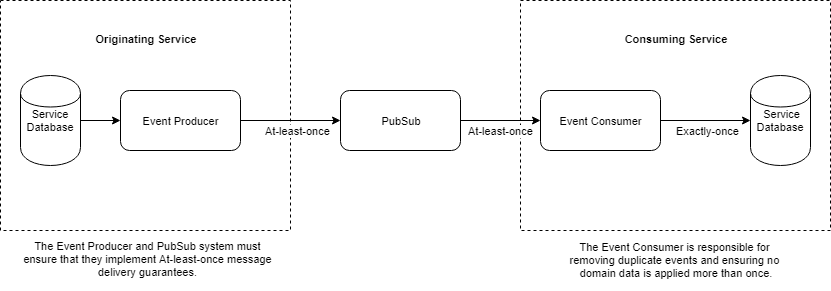
The data needs to be encoded / serialized for efficient transfer using the Pub/Sub system and subsequently decoded / de-serialized in the Event Consumer.
Considering that the event data also needs to be persisted to a relational database, it makes sense to encode the event data before it is persisted as it avoids having to implement a different table for each event type. Although storing data in an encoded format in a database is not ideal, it is unlikely that there will be a need support querying for event data in the originating service.
Events effectively replace the role of traditional IPC mechanisms for inter-service communications. For this reason it is important that the event data conforms to a known structure. Knowing this structure, or schema, allows the Consuming Services to utilize and rely on the data contained in events.
The following would thus be important considerations when deciding on an encoding mechanism for event data:
- A set schema is used to encode and decode event data. The schema details the names and types of the fields contained in the encoded data structure.
- The schema is well documented so that there is a clear understanding between the Originating Service and the Consuming Services.
- The schema is available to all services that require it, ideally in a central schema repository
- The schema’s can evolve without breaking forward or backward compatibility
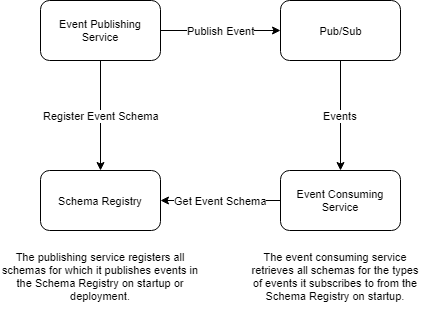
A Schema Registry
A Schema Registry is an independent service that is solely responsible for storing and retrieving event schemas. Originating Services are able to register an event schema with the Schema Registry service so that Consuming Services are able to retrieve it. The Consuming Services subsequently use the schemas to decode the events published by the Originating Services.
A Database Schema for Events in the Originating Service
Once the event data is encoded it can be persisted to the database. The following schema can be used to persist events in the local relational database used by the originating service (any service that publishes events).
* – denotes a required field
*id – A GUID / UUID that identifies the event. The ID is essential to remove duplicates by any consumers that subscribe to this particular event type.
*sequence – An auto-incrementing sequence number that helps to maintain the order of events. The Event Publisher must always sort by the sequence when retrieving events from the database to publish to the Pub/Sub system.
*data – The encoded binary data of the event itself. This encoded data forms the core of the message that is sent by the Event Publisher to the Pub/Sub system.
*event_source_id – An identifier of the object that caused the event to be fired. One event_source_id could be linked to many events. In Domain Driven Design terms, this field refers to the unique identifier of the Aggregate Root. Effectively, it serves as a grouping mechanism for events. In Event Sourcing systems, if all the events linked to a specific event_source_id were replayed, it would be possible to reconstruct the state of the Aggregate Root.
For example, in a virtual wallet application, an event “Transaction Added” could define an event_source_id as the primary key of the account that triggered the event. If all the events for an account were replayed, you could calculate the account balance at any given time.
This field will not always link to a Domain object, hence it is simply referred to as the Event Source (e.g. an Email Service publishing an Email Failed event won’t necessarily link to any domain data).
This field can be used by the Pub/Sub system to group related events so that a single Event Consumer can consume related events in order. The order can be extremely important – in our Virtual Wallet, you cannot apply a debit transaction to an account that does not exist – you would need to process an Account Created event first.
event_source_name – A string field that indicates the type of the event source. In our “Transaction Added” example, the event_source_name would be “Account”. This column is not strictly necessary for the Event System, but could provide useful trace-ability – together with the event_source_id, it allows us to query for data related to the event.
schema_version – The version of the schema that was used to encode the data for an event. Only needed if the event data needs to be decoded at a later stage.
schema_name – The name of the schema that was used to encode the data for an event. Only needed if the event data needs to be decoded at a later stage.
created_at: A date/time that indicates when an event was created. While not strictly necessary for the event system, it could be helpful to determine scaling requirements for the Event Publisher by determining the difference between the created_at time and the published_at time. It can also be used by an archiving system if we wish to remove or archive older events.
published_at: The time at which the event was published to the Pub/Sub system. This allows the Event Publisher to query for unpublished events. Once an event is published to the Pub/Sub system, the published_at date/time is updated, indicating that the event has been published successfully.
Event Lifetime in an Originating Service
There is no need to keep events once they have been published by the Event Publisher to the Pub/Sub system. There are two options to consider when implementing the Event Producer:
- Delete the event from the event table once it has been published or
- Set the “published_at” date/time once the event has been published
There are some advantages to keeping the events after they have been published:
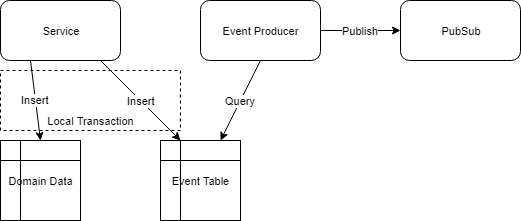
- It is possible to query the domain data that caused the event to be triggered (provided the event_source_id and event_source_name is saved)
- It could be helpful for scaling purposes to check the difference between the created_at and published_at date/times. Big differences could indicate that the publisher/s are overloaded.
However, a script to archive events older than a specific date will need to be implemented.
A Database Schema for Events in the Consuming Service
The Event Consumer needs to keep track of which events have already been processed as events could be duplicated. For this reason, we need to persist the GUID / UUID of the event that has been processed. A possible schema:
* – denotes a required field
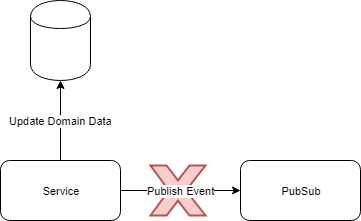
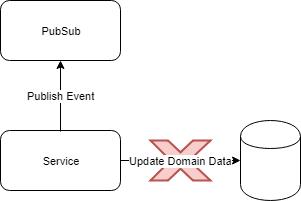
*id – A GUID / UUID that identifies the event. The ID is essential to prevent events which have been processed already from being processed again. This ensures that the consumption of events and subsequent update of domain data is an idempotent operation. Note: It is important to implement a unique constraint on this field. This caters for race conditions where multiple consumers could attempt to process duplicates of the same event simultaneously. The unique constraint will fail the transaction, preventing the domain data from being duplicated.
received_at – A date/time that indicates when the event was received. This is required for archiving older events, but can be omitted if events are never archived.
Note – If the database or storage system of the Consuming Service is not a relational database, it is still possible to add the event ID and the domain data atomically. The only requirement is that the event ID is stored in the same record / document / row as the domain data and added during the same, single operation as the domain data. E.g. In MongoDB, the event ID could be added to the document that contains the domain data.
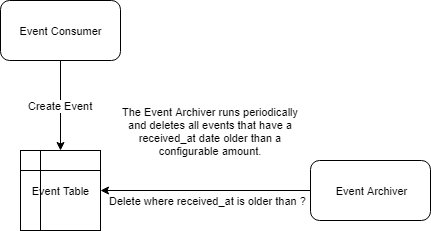
Event Lifetime in a Consuming Service
Events in the Consuming Service must be persisted for a minimum period of time. This period is determined by two factors:
- The time period one could reasonably expect duplicates of the same event to still be received in the event of communication or catastrophic failures
- Whether or not the events from either the originating service or events from the Pub/Sub system could be replayed.
In event sourcing systems, events could conceivably be replayed from service inception in order to rebuild the data in dependent services. For this use case, it might be required to store events indefinitely.
If event replay is not a use case to consider, the Consuming Service, as with the producing service, needs to implement an Event Archiver:
Events and Pub/Sub Topics
It is generally recommended to use a separate topic in the Pub/Sub system for every schema used to encode data. The schema of each event will be different, so it makes sense to have a one-to-one mapping between events and topics. The topic names can match the names of the events.
Kafka as the Pub/Sub system
Kafka is a proven, scalable, publish-subscribe messaging system. In comparison to most messaging systems Kafka has better throughput, built-in partitioning, replication, and fault-tolerance which makes it a good solution for large scale message processing applications.
Advantages:
- Very good write performance
- Multiple consumers per topic
- Cluster-level fault tolerance: Kafka has a distributed design that replicates data per-topic and allows for seamless handling of individual node failure.
- Data retention for message replay: Kafka has a unique “distributed commit log” design to its topics, which makes it possible to replay old messages even if they have already been delivered to downstream consumers. This allows for various data recovery techniques that are typically unavailable in pub-sub systems.
Apache Avro as an event data encoding format
Avro is a data serialization framework which relies on schema’s. The schema’s are required for both read and write operations.
Benefits:
- Libraries available for most major languages
- Data is serialized into a very compact binary format
- Schemas can be evolved in a backward compatible fashion
- Does not rely on code generation like some other systems
Confluent as a Service Registry
Confluent is an open-source streaming platform built to run alongside Apache Kafka. It includes a Service Registry which exposes a REST API.
The Service Registry allows configurable compatibility rules and exposes an endpoint to enable compatibility checking of new schema’s before they are registered. Schema’s are automatically versioned when registered and clients are able to either request the latest schema or a specific version of the schema of a subject.
Confluence also includes the Kafka REST Proxy which provides a RESTful interface to a Kafka cluster in order to produce and consume messages, view the state of the cluster, and perform administrative actions without using the native Kafka protocol or clients.